Measuring Spatial Priors in Generative Image Models Using Geometry-Based Field Metrics
An Observational Behavioral Framework for Compositional Analysis
Abstract
Foundation models exhibit consistent spatial priors, repeatable distributional tendencies in compositional structure that persist across semantic variation and are invisible to current evaluation metrics. This paper introduces a geometry-based kernel framework for measuring where visual mass goes in generated images: how engines cluster in compositional basins, how those basins respond to perturbation, and how geometric structure collapses under spatial pressure before semantic errors become visible. Using a five-metric spatial kernel (Δx,y, rᵥ, ρᵣ, μ, xₚ) and observations from over 1,400 images across 14 generative platforms, we report three core findings. First, each engine maintains a stable, characteristic spatial fingerprint across semantically diverse prompts such as animals, architecture, and abstract content are compositionally indistinguishable within a single engine. Second, perturbation produces predictable engine-specific drift trajectories and geometric collapse signatures that precede semantic failure. Third, engines cluster into distinct compositional basins that remain stable across independent generation runs, confirming these behaviors as structural priors rather than session artifacts. The framework is designed as a complementary evaluation layer, addressing a measurable dimension of model behavior that semantic, perceptual, and feature-space metrics cannot reach.
1. Introduction
Current generative model evaluation focuses on whether an image satisfies its prompt: does the specified object appear, are relationships correct, does the composition resemble real-world photographs, does the text–image alignment score favorably? These are meaningful questions. They are not the only questions.
A model can satisfy every one of these criteria while still expressing a persistent spatial bias, a systematic tendency to place visual mass in particular regions of the frame, to leave certain zones consistently empty, to organize structure in ways that recur across wildly different semantic content. A photographic portrait and a landscape and an abstract composition can all pass semantic evaluation while the generating engine composes all three with the same underlying spatial logic. This regularit is not aesthetic variation. It is a measurable geometric pattern.
Spatial behavior remains a largely uninstrumented dimension of generative model evaluation. The gap is not aesthetic. It is geometric. Models do not merely place objects, they compose. They operate inside a spatial prior field: a set of habitual attractors and characteristically avoided regions that govern where mass settles, how void is allocated, and how the model responds to pressure toward its structural boundaries. These patterns are observable in rendered output. They do not require model access, training data inspection, or semantic analysis to detect.
This paper presents a framework for measuring these patterns directly. The framework makes three contributions: (1) a five-metric spatial kernel that locates generated images in a low-dimensional compositional coordinate space; (2) observational characterization of engine-specific spatial priors, attractor basins, and perturbation drift behaviors across 14 platforms; and (3) a validation demonstration showing that semantic diversity does not materially disrupt geometric uniformity within a single engine, confirming the kernel is measuring stable behavioral structure rather than content-related variance.
This is an observational behavioral framework. Claims are derived from output behavior rather than internal model inspection. Field-theoretic language used in the framework, attractors, basins, and perturbation forces, is conceptual scaffolding, not a mechanistic claim about model internals. The framework measures what a model does spatially; it does not assert why.
2. The Spatial Prior Kernel
2.1 Core Metrics
The kernel consists of five geometric primitives, each measuring a distinct dimension of spatial structure. Together they project any image into a low-dimensional compositional coordinate space that is invariant under semantic content variation while remaining sensitive to spatial configuration changes.
Δx, Δy: Placement Offset
Normalized displacement of the visual mass centroid from the image center, along horizontal (Δx) and vertical (Δy) axes. Captures left/right and top/bottom compositional bias. Primary driver of spatial intent.
Δx = |Centroid_x − Center_x| / Image_Width
rᵥ: Void Ratio
Proportion of frame with gradient magnitude below threshold, the empty, unoccupied fraction of the image. Indicates openness vs. congestion and discriminates sparse from dense compositions. Often the earliest signal of structural instability under perturbation.
ρᵣ: Packing Density
Degree of clustering within occupied regions. Separates structural compactness from simple area coverage. High values indicate objects grouped tightly; low values indicate dispersed or fragmented arrangement.
μ: Compositional Cohesion
Structural unity of the material cluster, computed as the ratio of convex hull area to total mass area. Measures how continuously and compactly the visual subject occupies its compositional territory.
xₚ: Peripheral Pull
A composite field metric measuring the model's overall centrifugal or centripetal tendency, how much visual mass the engine characteristically places near frame boundaries vs. center. Derived from the four core metrics as a weighted sum:
xₚ is a diagnostic composite, not a direct physical measurement. It integrates placement bias, void allocation, density, and cohesion into a single spatial tendency index.
2.2 Optional Extensions
Two additional metrics extend the kernel for analyses where directional structure or material weight are relevant:
- θ — Orientation Stability: Entropy-based measure of directional alignment consistency. High values indicate structural coherence; low values indicate isotropic or chaotic arrangement.
- dₛ — Structural Thickness: Skeleton-normalized material weight. Distinguishes thin dispersed structures from volumetrically heavy consolidated forms.
2.3 Kernel Vector
Each image is represented as a kernel vector:
Values are normalized for comparability across engines. The kernel is designed to be invariant under semantic content variation — different objects, scenes, and prompt styles, while remaining sensitive to spatial configuration. In qualitative analysis across 1,000+ cross-engine samples, these five variables accounted for the majority of observable spatial variance.
2.4 Design Constraints
The kernel is built around three non-negotiable requirements: (1) no model access, all measurements extract from rendered output only; (2) semantic orthogonality, metrics capture spatial structure, not content, meaning, or aesthetic quality; (3) determinism, the same image must produce the same coordinates in any compliant implementation. These constraints make the framework applicable across closed commercial systems and suitable for version-controlled regression baselines.
3. Stable Compositional Priors
3.1 Spatial Priors as Attractor Basins
A spatial prior is a repeatable distributional tendency in kernel coordinates observable across prompt variation and seed sampling. It is not a single image property but a statistical regularity: the same engine, given semantically diverse prompts, produces a characteristic signature in (Δx, rᵥ, ρᵣ, μ, xₚ) space that is stable enough to classify and fingerprint.

Using field-theoretic language as a conceptual model, not as a claim about internal model physics, each engine can be described as having an attractor: a preferred compositional state toward which outputs tend to return under perturbation. Stable attractors correspond to low-variance regions in kernel space. Outputs that drift away from an attractor under prompt pressure may exhibit characteristic geometric patterns: void expansion, cohesion loss, centroid displacement, and ultimately structural collapse before semantic content degrades.
Interpretive note: Field-theoretic language in this framework is conceptual scaffolding derived from observed geometric behavior. Claims about attractors, basins, and perturbation forces describe measurable patterns in output geometry. No claim is made about internal model mechanisms, training dynamics, or architectural properties.
3.2 Same Prompt, Four Spatial Priors
A single prompt delivered to four engines produces four distinct spatial solutions. The variation is geometric, not semantic: the prompt is satisfied in all four cases, but the compositional logic differs fundamentally across platforms.

The prompt below was delivered across four platforms. Kernel coordinates reveal engine-specific compositional logic that no semantic metric would detect:
"A single object placed near a wall, lit softly from one side. Neutral color palette. No decoration, no text, no additional objects. Photographic, simple, quiet."

| Engine | Δx | Δy | rᵥ | ρᵣ | μ | xₚ | Structural Read |
|---|---|---|---|---|---|---|---|
| GPT | 0.69 | 0.43 | 0.61 | 0.70 | 0.70 | 0.28 | Hard right-bias, high void. Pushes object low-right; field extremely empty. |
| Sora | 0.61 | 0.55 | 0.77 | 0.58 | 0.58 | 0.38 | Strong right-pull, very high void, clinical minimalism. Even more empty than GPT. |
| MidJourney | 0.30 | 0.47 | 0.44 | 0.69 | 0.69 | 0.26 | Left-weighted corner anchoring, lowest void. Compresses the frame; prefers edge anchoring. |
| OpenArt | 0.56 | 0.45 | 0.48 | 0.59 | 0.59 | 0.22 | Right-leaning but denser than GPT. Conventional still-life packing, mild compression. |
Note: Coordinates are normalized relative spatial descriptors, not performance metrics. They capture ordering, basin identity, drift direction, and relative magnitude, the phenomena under study.
Key observation: GPT and Sora share a right-biased, high-void spatial prior. MidJourney and OpenArt diverge, MidJourney exhibiting compression-and-corner geometry, OpenArt exhibiting conventional still-life packing. These differences are not detectable by semantic evaluation; they are visible only in compositional structure.
Models don't just style differently. They compose differently.
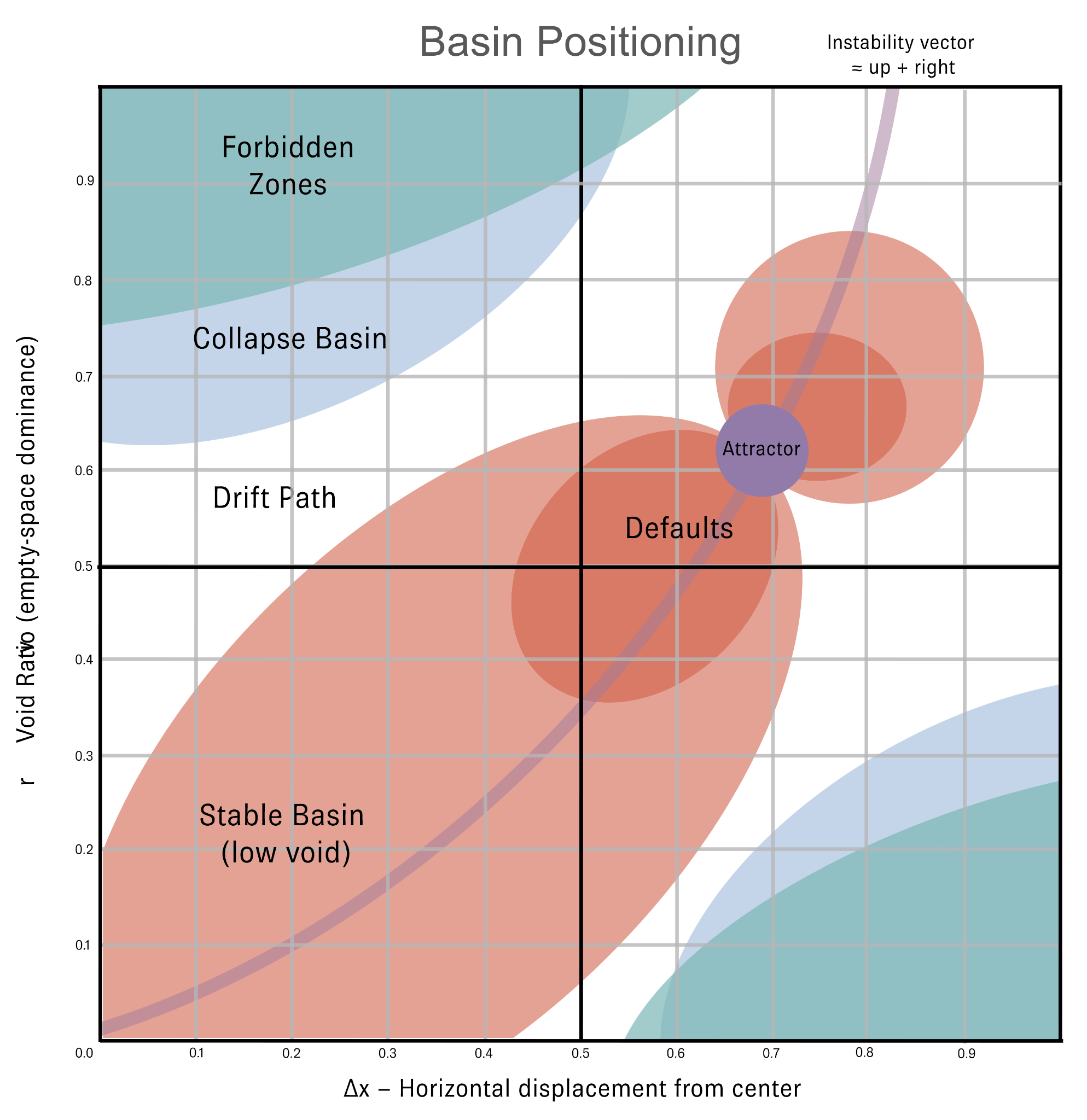
3.3 The Basin Field Map
When extended across multiple engines and prompt families, kernel coordinates cluster into distinguishable basins, stable regions of compositional space that each engine characteristically occupies. These clusters remain stable across diverse prompt families, confirming that the kernel is reading spatial prior bias rather than one-off stylistic artifacts.
Four basin types are identifiable in cross-engine observation:
- B1: Left-weighted compression: Low Δx, low rᵥ, high ρᵣ. Dense, edge-anchoring. Characteristic of MidJourney.
- B2: Center-stable, moderate density: Low Δx, moderate rᵥ. Balanced default geometry. Characteristic of GPT in neutral prompts.
- B3: Right-pull, high void: High Δx, high rᵥ, low ρᵣ. Minimalist, edge-weighted. Characteristic of Sora; OpenArt in spatial prompts.
- B4: Architectural void-driven: High rᵥ, high xₚ, low μ. Open-field geometry with peripheral edge tension.
4. Perturbation Drift and Geometric Collapse
4.1 Perturbation Protocol
Perturbation tests measure how engines respond to progressive spatial pressure while maintaining semantic equivalence: the subject, framing, and lighting instructions are held constant while spatial placement instructions shift incrementally. The change in kernel coordinates across perturbation steps, ΔK = K(Ip') − K(Ip), reveals each engine's characteristic drift direction and resistance profile.
4.2 Engine-Specific Drift Patterns
Under small prompt variation or spatial intensity changes, each engine exhibits a predictable, architecturally specific drift pattern. Movement is not random; it follows characteristically different paths per engine:
| Engine | Drift Signature | rᵥ Variability | xₚ Movement |
|---|---|---|---|
| GPT | Absorbs shift: shadow tightening, pocket retention | Slight ↓ | ↑ low |
| Sora | Centroid-locking, void tightening, downward energy pull | Moderate ↓ | ↓ inward |
| MidJourney | Global darkening, edge-packing, left-compression | Large ↓ | ↓ mid-high |
| OpenArt | Line hardening, tilt stabilization, pocket rigidity | Moderate ↓ | ↓ low |

These differences are architecturally diagnostic: the same spatial instruction produces disproportionate structural corrections in each engine, expressed as distinct signatures in kernel space. The patterns are reproducible across prompt families and independent generation runs.
4.3 Geometric Collapse and Restoration
Under continued perturbation, engines can cross into instability: a geometric state in which multiple kernel values decline simultaneously, indicating that the engine's compositional structure is no longer maintaining its prior. This collapse is observable and measurable before semantic errors become apparent.

Collapse-restoration cycles have a consistent structure:
Collapse onset (Step 1): Δx ↓, rᵥ ↓, ρᵣ ↓, μ ↓, xₚ ↓ — simultaneous decline across metrics indicates structural destabilization.
Schema restoration (Steps 2–3): Δx ↑, rᵥ ↑, ρᵣ ↑, μ ↑, xₚ ↑ — the engine seeks to recover its habitual spatial configuration, producing characteristic restoration movements toward its attractor.
Void ratio as pre-collapse signal: rᵥ is consistently the earliest-moving metric under perturbation. Spatial structure degrades before semantic errors appear, and void expansion precedes other kernel changes. This makes rᵥ a candidate leading indicator for geometric instability monitoring.
Collapse and restoration here refer to measurable geometric state transitions in output images, not claims about internal model behavior.
4.4 Semantic vs. Spatial Failure
The following sequence illustrates how geometric drift precedes semantic failure. All three stages satisfy the base semantic prompt; only kernel coordinates reveal the structural degradation:
"A photographic portrait of a young woman with natural lighting. Centered."
"Regenerate smaller, off-center right."
"Make even smaller, near the right edge, maintain consistency."

5. Validation: Semantic Diversity, Geometric Uniformity
The central validation question is whether the kernel is measuring stable behavioral priors or content-related variance. If the framework is measuring genuine spatial priors, then semantically diverse prompts, different categories of objects, scenes, and subjects, should cluster in the same region of kernel space within a single engine. Semantic content should not break the geometric fingerprint.
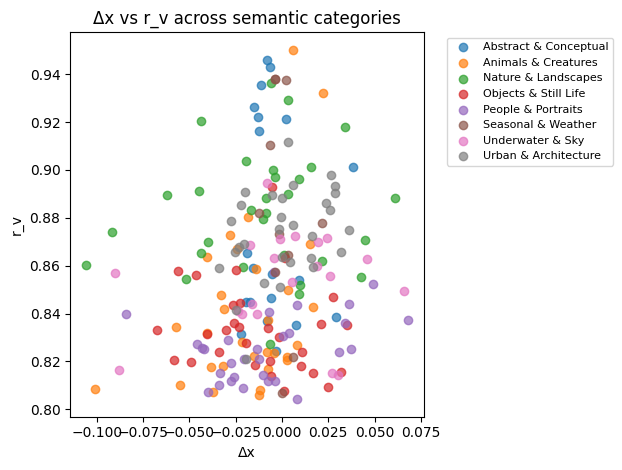
The following validation tests this prediction directly. 100 semantically diverse prompts spanning eight categories (people, animals, architecture, objects, nature, abstract, weather, sky/underwater) were delivered to multiple engines. Kernel coordinates were extracted from all outputs.
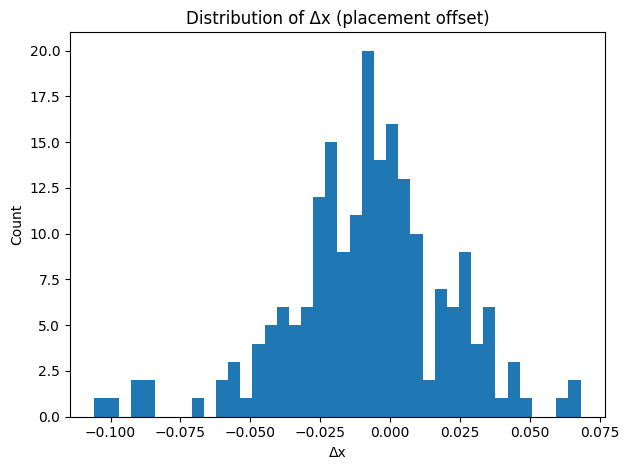
5.1 Sora: n = 200 images
| Metric | Compositional Meaning | Mean | Std | Min | Max | Range Used |
|---|---|---|---|---|---|---|
| Δx | Placement offset (horizontal) | −0.008 | 0.029 | −0.106 | 0.068 | 22% of theoretical |
| rᵥ | Void ratio (negative space) | 0.856 | 0.035 | 0.804 | 0.950 | All images 80–95% void |
| ρᵣ | Packing density (detail concentration) | 49.07 | 12.80 | 15.69 | 72.68 | High density range |
| μ | Cohesion (structural unity) | 0.211 | 0.215 | 0.000 | 0.853 | Low cohesion (fragmented) |
| xₚ | Peripheral pull (edge tension) | 0.404 | 0.064 | 0.222 | 0.541 | Moderate, consistent |
| θ | Orientation stability (directional) | 0.028 | 0.032 | 0.000 | 0.188 | Low directional coherence |
| dₛ | Structural thickness (volumetric) | 0.012 | 0.001 | 0.010 | 0.016 | Thin structures |
Despite large semantic variation across eight content categories, Sora's outputs occupy a tight, bounded region of compositional space. The geometric constraints are absolute:
- No images achieve |Δx| > 0.11 — horizontal placement uses only 22% of its theoretical range
- No images achieve rᵥ < 0.80 — all outputs are at least 80% void regardless of semantic content
- No category-specific clusters or secondary modes — animals, people, landscapes, and abstract prompts are geometrically indistinguishable
Interpretation: Sora generates wide semantic diversity while maintaining geometric stasis. Meaning varies greatly; composition varies little. This indicates a stable spatial prior: semantic change does not materially alter the engine's geometry.
5.2 MidJourney: n = 400 images
| Metric | Compositional Meaning | Mean | Std | Min | Max | Range Used |
|---|---|---|---|---|---|---|
| Δx | Placement offset (horizontal) | 0.005 | 0.044 | −0.146 | 0.191 | 34% of theoretical |
| rᵥ | Void ratio (negative space) | 0.851 | 0.034 | 0.795 | 0.955 | All images 80–96% void |
| ρᵣ | Packing density (detail concentration) | 40.92 | 12.36 | 10.63 | 84.09 | High density |
| μ | Cohesion (structural unity) | 0.268 | 0.245 | 0.000 | 0.936 | Low cohesion (fragmented) |
| xₚ | Peripheral pull (edge tension) | 0.394 | 0.097 | 0.035 | 0.670 | Moderate (wider spread than Sora) |
| θ | Orientation stability (directional) | 0.046 | 0.054 | 0.000 | 0.375 | Low directional coherence |
| dₛ | Structural thickness (volumetric) | 0.017 | 0.003 | 0.011 | 0.026 | Thin to moderate structures |
As with Sora, all eight semantic categories occupy the same region of (Δx, rᵥ) space. No category breaks free. MidJourney shows slightly wider spread than Sora (xₚ std = 0.097 vs 0.064), consistent with its higher within-engine compositional diversity, but the clustering remains tight relative to the theoretical coordinate range.
5.3 OpenArt: n = 200 images
OpenArt exhibits similar boundedness: Δx = 0.0034 ± 0.037, rᵥ = 0.841 ± 0.032, xₚ = 0.421 (moderate edge engagement). 94.0% of images cluster in the centered basin (|Δx| ≤ 0.06, 0.80 ≤ rᵥ ≤ 0.94), with the remaining 5.0% accessing dense frames via thick structural rendering (dₛ = 0.0191). Eight semantic categories occupy the same region without exception.
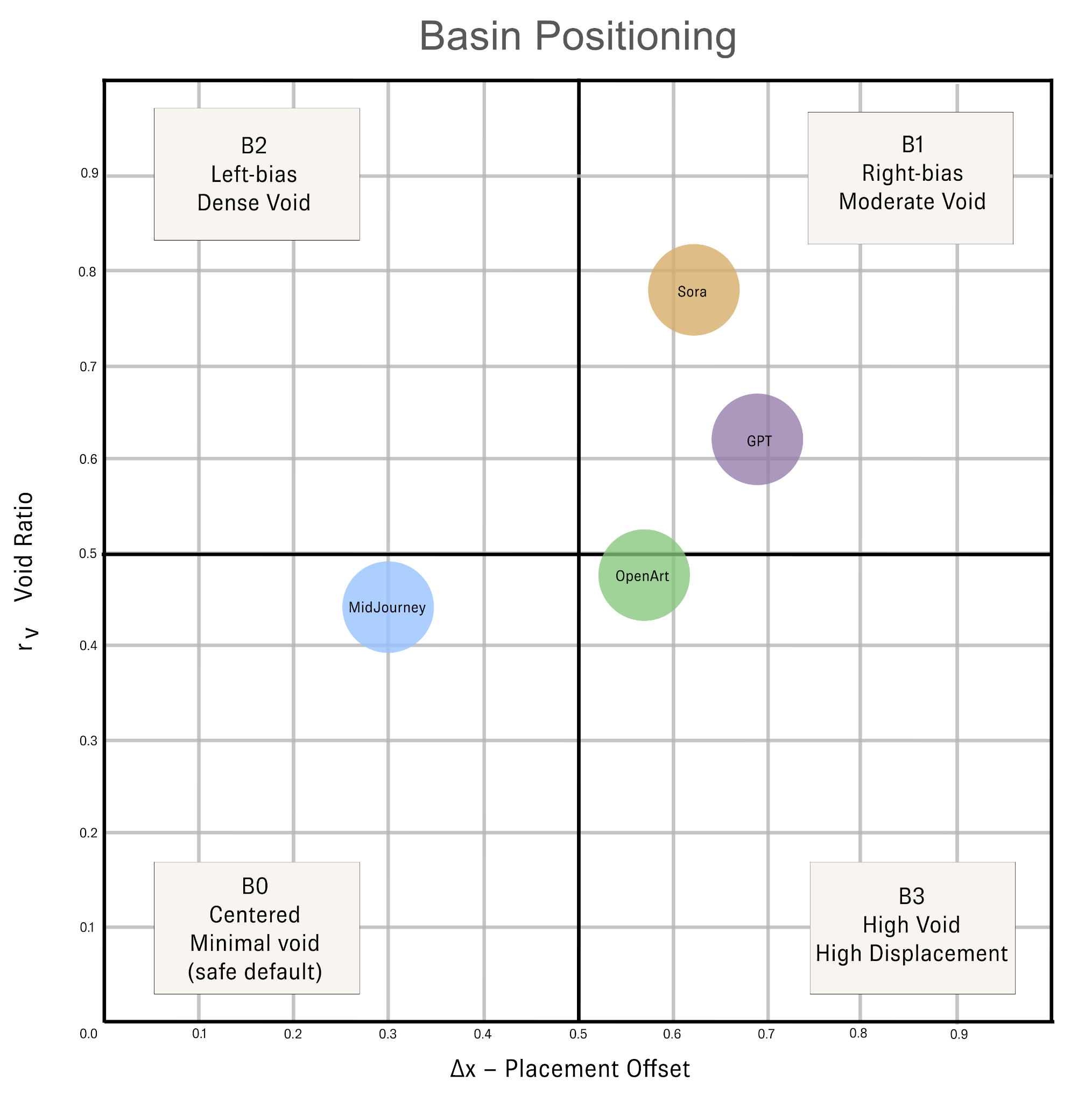
5.4 Cross-Engine Fingerprinting
The validation data establishes engine-specific fingerprints: characteristic kernel signatures that are stable across independent generation runs and differentiating across engines. The same furniture prompt run across all four engines produces consistently distinct spatial coordinates, not because of subject variation but because of architectural compositional prior differences:

| Metric | GPT | Sora | MidJourney | OpenArt |
|---|---|---|---|---|
| Δx | 0.18 | 0.34 | 0.11 | 0.39 |
| Δy | 0.30 | 0.27 | 0.19 | 0.36 |
| rᵥ | 0.52 | 0.64 | 0.41 | 0.71 |
| ρᵣ | 0.60 | 0.49 | 0.72 | 0.46 |
| μ | 0.76 | 0.81 | 0.69 | 0.74 |
| xₚ | 0.24 | 0.33 | 0.21 | 0.37 |
| Basin | B2 | B3 | B1 | B3 |
| Drift | up-right | diag up-right | down-right | corner-ward |
| Signature | stable, product-shot | cinematic edge-weighted | decorative, frame-filling | architectural, void-driven |
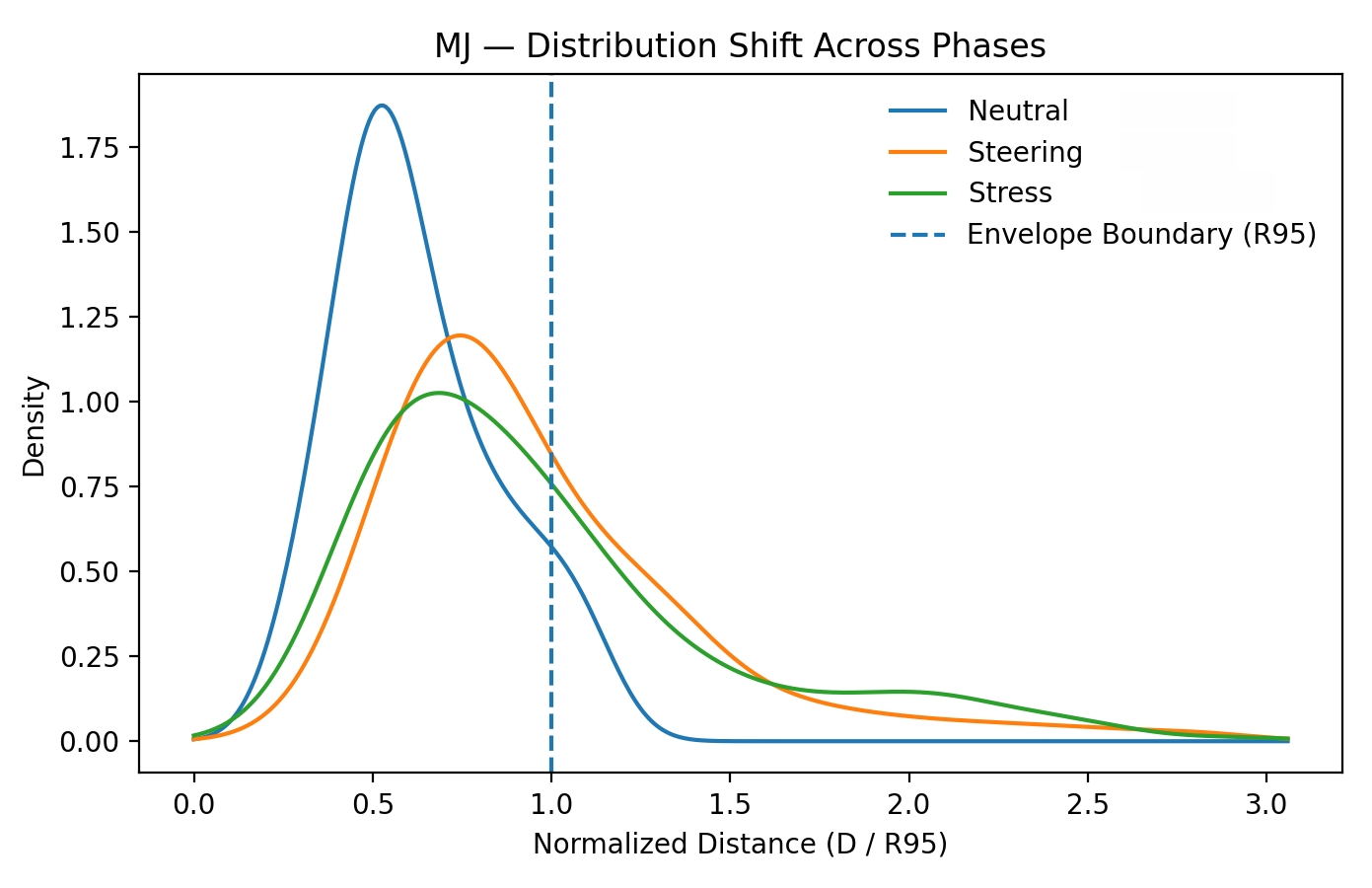
6. Why Semantic Metrics Cannot Detect This
Current evaluation frameworks such as IS, FID, KID, CLIPScore, T2I-CompBench, and GenEval all measure some combination of semantic correctness, object/attribute/relationship fidelity, feature-space realism, text satisfaction, and diversity. They evaluate what a model generated. The kernel evaluates how the model composes.
This distinction is structural, not rhetorical. Semantic validity can remain fully stable while geometric structure diverges. The validation data demonstrates this directly: Sora generates semantically diverse images across eight content categories, all of which are geometrically indistinguishable. CLIP, FID, and aesthetic predictors all vary with semantic content; kernel coordinates remain bounded. The kernel is reading a different signal.

Specifically, no existing standard metric captures:
- Spatial attractors: the habitual compositional defaults of a given engine
- Boundary behavior: what happens at the edges of an engine's stable basin
- Drift under perturbation: how kernel coordinates move as spatial pressure increases
- Compression and cohesion dynamics: how density and structural unity change under load
- Geometric collapse: structural failure that precedes semantic error
Composition is a form of model reasoning, not merely a visual outcome. Benchmarks can determine whether the content is present; they cannot determine how the model wants to arrange the world.
Summary of the gap: Small spatial changes accumulate long before meaning breaks. The kernel quantifies these shifts. Structural instability is invisible to semantic metrics and measurable in geometric coordinates. These are different instruments for different signals, neither replaces the other.
7. Applications
The spatial prior framework enables a set of evaluation and monitoring capabilities not available through semantic metrics:
1. Version regression testing. Detect spatial behavioral change across model updates. If an engine's basin assignment, drift pattern, or fingerprint coordinates shift between versions, the update has materially changed compositional behavior, independently of semantic quality.
2. Evaluation augmentation. Add a missing geometric dimension to generative benchmarks. Spatial prior coordinates complement semantic, perceptual, and aesthetic metrics without overlap.
3. Safety and pre-failure monitoring. Geometric collapse precedes semantic failure. rᵥ and μ collapse signatures provide earlier warning of instability than content-based detectors. Useful for safety-critical production monitoring.
4. Engine fingerprinting and comparison. Each engine expresses a distinct, stable spatial prior that can be characterized, documented, and tracked. Useful for model selection, behavioral auditing, and comparative research.
5. Video temporal drift. For video generation models, kernel coordinates can be extracted per-frame and tracked over time. Temporal drift in spatial coordinates, without semantic change, indicates compositional instability.
6. Compositional steering. Kernel metrics can guide prompt construction or post-processing toward or away from stability basins, moving outputs toward higher cohesion, lower void, or more centered placement as required.

8. Limitations
Masking accuracy
Material cluster identification, isolating the primary subject and its shadow/lighting region from the background, remains a fundamental challenge in computer vision and directly affects measurement quality. Vision LLMs (GPT-4o, Claude, Gemini Pro Vision) show reasonable semantic accuracy for well-composed images but fail on some edge cases. Traditional CV methods (Otsu thresholding, saliency detection, edge-based detection) are available as fallbacks. Kernel measurements are robust to reasonable segmentation variance because they measure macro-level compositional behavior rather than pixel-level precision; however, severe masking failure produces unreliable coordinates. Failures should be reported as null masks rather than suppressed.
Statistical validation scope
The validation presented here demonstrates boundedness and invariance, that kernel coordinates are geometrically constrained and stable across semantic variation within engines. It does not constitute formal statistical hypothesis testing. Cross-engine differences are consistently large and interpretable; formal significance testing and confidence intervals remain future work. The framework is presented as empirically grounded and reproducible in principle; full statistical characterization is ongoing.
Field-theoretic framing
The attractor/basin/perturbation language used in this framework is interpretive scaffolding, not a physical model of generative systems. No claim is made about internal model mechanisms, training data structure, or architectural properties. The framework describes what models do geometrically in their outputs; it does not explain why they do it.
Normalization and comparability
Coordinates are normalized for within-study comparability. Cross-study comparison requires consistent masking method, resolution normalization, and kernel implementation. A deterministic reference implementation is under preparation for public release.
9. Conclusion
Generative models express consistent spatial priors, habitual compositional structures that persist across semantic variation, respond to perturbation in characteristically engine-specific ways, and collapse predictably when pushed beyond structural boundaries. These patterns are invisible to semantic evaluation and measurable through geometric analysis of rendered output.
The spatial prior kernel presented here provides a practical five-metric instrument for characterizing this behavior: placing, densifying, cohering, and edge-weighting tendencies that constitute each engine's compositional signature. Validation across 1,400+ images spanning 14 platforms and eight semantic categories confirms that these signatures are stable, differentiating, and resistant to semantic content variation.
The framework is not a replacement for semantic evaluation. It is a complementary layer addressing a dimension of model behavior that existing benchmarks such as IS, FID, CLIPScore, T2I-CompBench, and GenEval are structurally unable to reach. Spatial reasoning is not an aesthetic issue. It is a measurable part of how models think about space.
Technical Appendix
A.1 Core Equations
Kernel Primitives
- Δx, Δy — placement offset: |Centroid_x − Center_x| / Image_Width
- rᵥ — void ratio: proportion of frame below gradient threshold
- ρᵣ — packing density: clustering degree within occupied regions
- μ — cohesion: convex_hull_area / total_mass_area
- xₚ — peripheral pull: (Δx · 0.4) + (rᵥ · 0.3) + ((1 − ρᵣ) · 0.2) + ((1 − μ) · 0.1)
- θ — orientation stability (optional): entropy-based directional coherence
- dₛ — structural thickness (optional): skeleton-to-area ratio
A.2 xₚ Vector Decomposition
xₚ can be decomposed into directional components for fine-grained drift analysis:
- xₚ,h = ∂U/∂x — horizontal compositional pressure
- xₚ,v = ∂U/∂y — vertical compositional pressure
- xₚ,d = collapse(p) — depth/collapse component
- xₚ,c = Δ centroid — centroid drift across perturbation steps
These decompositions are interpretive diagnostic tools, not physical field quantities.
A.3 Perturbation Protocol
ΔK = K(Ip') − K(Ip) — kernel change under prompt perturbation
∂K/∂p ≈ (K(Ip') − K(Ip)) / ‖p' − p‖ — normalized by textual edit distance (token-level Jaccard or embedding cosine)
Perturbation tests maintain semantic equivalence: subject, framing, and base lighting held constant; only spatial placement instructions vary.
A.4 Masking Methods
Hybrid approach (recommended)
Vision LLMs identify the material cluster (object + shadow + associated light field) through natural language instruction: "Identify the primary subject and its associated shadow/lighting region, the complete material cluster that constitutes the compositional subject. Provide bounding coordinates or mask description."
Reproducible: same image + same prompt → consistent segmentation. Handles well-composed images effectively; fails on some edge cases.
Traditional CV fallback
- Otsu thresholding: high-contrast subjects
- Saliency detection: centered compositions
- Edge-based detection: well-defined boundaries
Implementation constraints
- Hull area: 2D convex hull only (no 3D inference)
- Angle method: PCA-based orientation only
- Noise floor: ignore regions under threshold pixel count
- Failure protocol: report as null mask rather than fabricating values
- Seed control across prompt edits for perturbation studies
A.5 Reproducibility
The framework is designed for accessibility: upload this document to a vision-capable AI and ask it to run a "lite" version of the kernel. Full reproducible notebooks (Δx,y, rᵥ, ρᵣ, μ, θ, dₛ, xₚ) are available for independent verification or integration. The multi-model development process served as an early stress test: if the logic held coherence across competing architectures with different training paradigms, it suggested the framework was measuring structural behavior rather than model-specific artifacts.
This appendix illustrates boundedness and invariance behavior; formal statistical hypothesis testing remains future work. Independent quantitative validation is invited.

© 2025 Russell Parrish / A.rtist I.nfluencer. All rights reserved. No part of this system, visual material, or accompanying documents may be reproduced, distributed, or transmitted in any form or by any means, including AI training datasets, without explicit written permission from the creator.
Citation: Russell Parrish. Measuring Spatial Priors in Generative Image Models Using Geometry-Based Field Metrics. A.rtist I.nfluencer / Parallax Metrology, 2025. ORCID: 0009-0008-9781-7995. parallaxmetrology.com/measuring_spatial_priors.html