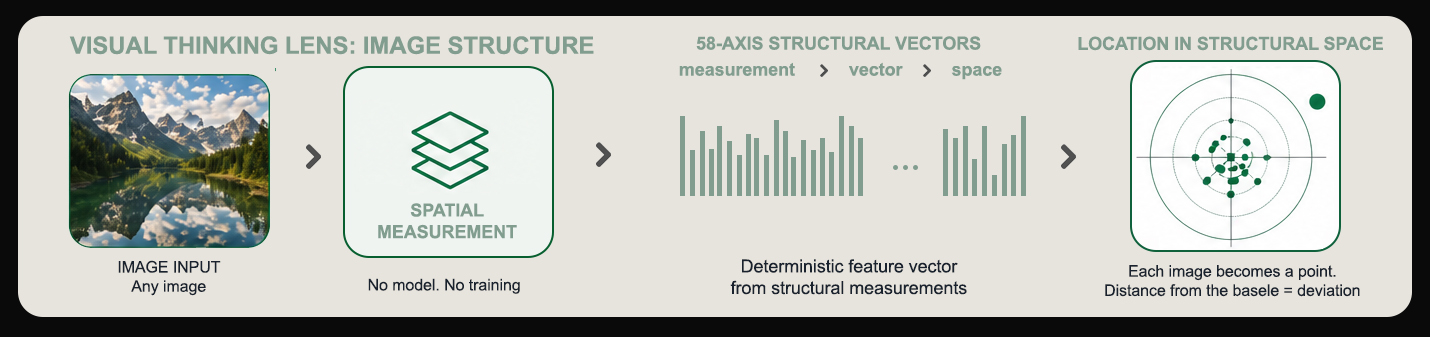
01 — Visual Thinking Lens
Image models repeat
the same geometry.
We measure it.
Semantic diversity explains less than 10% of observed spatial variance in text-to-image systems. Composition is not prompt-driven. It is prior model-driven. The VTL makes that prior visible, measurable, and comparable across engines.