Instrument Pipeline
Measure it.
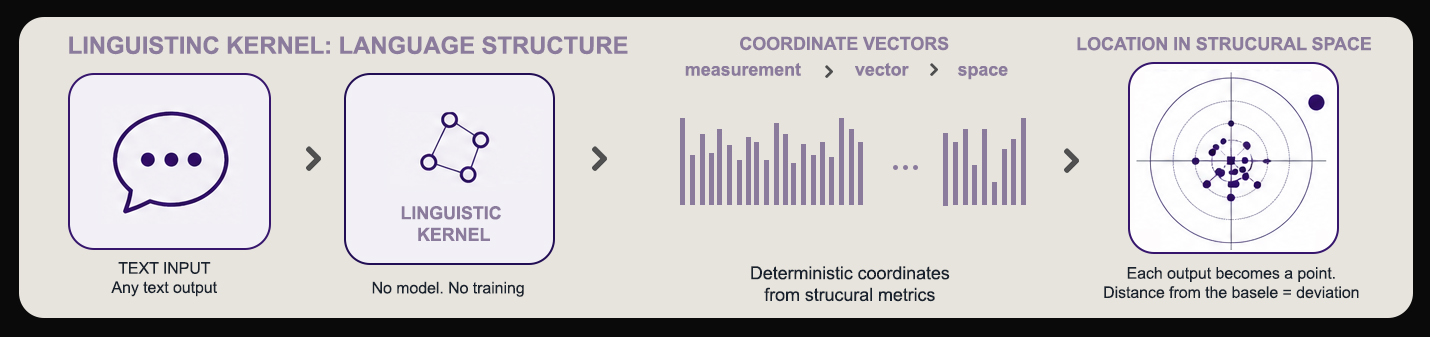
The Linguistic Kernel is a behavior-only instrumentation layer for large language model outputs. It reduces any text string to a reproducible coordinate in structural space — without calling another model, without semantic judgment, without guesswork.
Most evaluation frameworks for language models fall into two categories — and both have fundamental problems.
Tells you how a model behaves on curated test sets under controlled conditions. Tells you nothing about structural behavior under production pressure, across conversation turns, or when output constraints are stressed.
Introduces the circularity it is meant to avoid. You are using a stochastic, non-deterministic system to evaluate another stochastic system. The judge has its own structural biases, its own failure modes, its own drift.
The same input always produces the same output. No model in the loop. No stochastic components. Every number is backed by countable evidence features.
Every coordinate has a countable source. The evidence bundle exposes all raw features that drove the computation. Nothing is hidden in a neural network's judgment.
Measures only what is visible in the produced text. Works identically on GPT, Claude, Gemini, or any open-weight model. No model-specific calibration required.
The kernel reduces any text to a point in an eight-dimensional structural space. The first four are the canonical core. The second four are auxiliary. Each dimension captures something orthogonal — no two measure the same thing.
Where informational mass lands across the response. Front-loaded vs. back-loaded vs. centered. Computed as a weighted centroid over sentence position.
Structural air and breathing room. Captures paragraph density, bullet structure, short-sentence proportion, and average sentence length in a single composite.
Concentration of content-bearing tokens relative to connective language. High values mean lexically dense, information-packed delivery. Low values mean connective tissue dominates.
Continuity of discourse scaffolding. Counts transition markers and reference pronouns that stitch sentences together. High cohesion means explicitly linked structure.
Average sentence length relative to a 15-token neutral baseline. Tracks punctuation suppression, verbosity constraints, sentence boundary collapse.
Edge-seeking behavior. Measures word rarity against a 6,355-word common-English baseline (Zipf-grounded). Domain-agnostic: jargon in any field scores high.
Non-linear jumps between adjacent sentences. One minus mean cosine similarity between neighboring sentence token distributions. High values mean abrupt topic movement.
Clause stacking and subordination density. Counts true subordinating conjunctions and weighted punctuation markers per token. Measures sentence layering pressure.
Every kernel computation passes through a deterministic five-stage pipeline. No external service. No randomness. No hidden scoring model.
Text is split into words, sentences, and paragraph blocks. Bullet lines handled as structural units.
›Count every feature: tokens, sentences, transitions, pronouns, subordinators, contrast markers, rare words, metaphors.
›Evidence features transform into the eight kernel dimensions via defined, versioned mathematical functions.
›Basin assignment and rhetorical state derived from coordinates. Z-space normalization applied when a prompt-family baseline is fitted.
›Coordinate, basin, evidence bundle, rhetorical state, segmentation flag, and full versioning metadata returned as a structured dictionary.
from kernel_v19 import LinguisticKernel kernel = LinguisticKernel() result = kernel.compute("Your LLM output goes here.") # → kernel coordinate result["kernel"] # {"Δx": 0.004, "rᵥ": 0.068, "ρᵣ": 0.676, "μ": 0.490} # → auxiliary dimensions result["aux"] # {"Δy": 0.85, "xₚ": 0.567, "θ": 0.880, "dₛ": 0.526} # → rhetorical state and basin result["basin"] # "B0_centered_compact" result["evidence"]["rhetorical_state"] # "assertive" # → every count that produced those numbers result["evidence"] # full audit bundle
Understanding the limits of a measurement instrument is as important as understanding its capabilities.
Because the kernel is deterministic and engine-agnostic, it composes into a range of operational and research applications.
Establish a structural baseline for each major prompt family in your application. Instrument your inference pipeline to compute the kernel on sampled outputs. Alert on rising breach ratios — structural shifts often precede downstream failures.
Run the same prompt family through multiple models. Compare centroids, R95 radii, and breach rates under identical stress conditions. Different engines have different structural fingerprints — make those differences measurable.
Apply controlled perturbations — constraint additions, polarity flips, length compressions — and measure coordinate deltas. Δy is the primary steerability axis for constraint-type prompts. Identify which prompts are structurally elastic and which are anchored.
Track structural trajectory across conversation turns. Healthy conversations show moderate variation around baseline. Problematic ones show systematic drift with no recovery. Hysteresis measures whether the return path is symmetric with the departure path.
Structural collapse signatures — silence, refusal, constraint-induced degeneration — cluster in geometrically separable regions of kernel space. Elevated breach ratios are early warning signals detectable before content-level failure is visible.
Use the kernel as a structural excursion detector in adversarial testing. Prompts that push the model into unusual structural territory are visible as coordinate outliers before semantic evaluation identifies the problem.
Instrument Pipeline
The kernel has been validated across 4,000+ responses spanning Claude, GPT, and Gemini, covering 40+ conditions and 16 task types, plus a 300-response Jacobian perturbation study covering 60 prompt families across 5 perturbation variants.
Structural behavior is stable across runs. Constraint prompts induce deformation in predictable directions. Dialectical prompts produce directional movement distinct from constraint compliance. Collapse signatures are geometrically separable from normal operation.