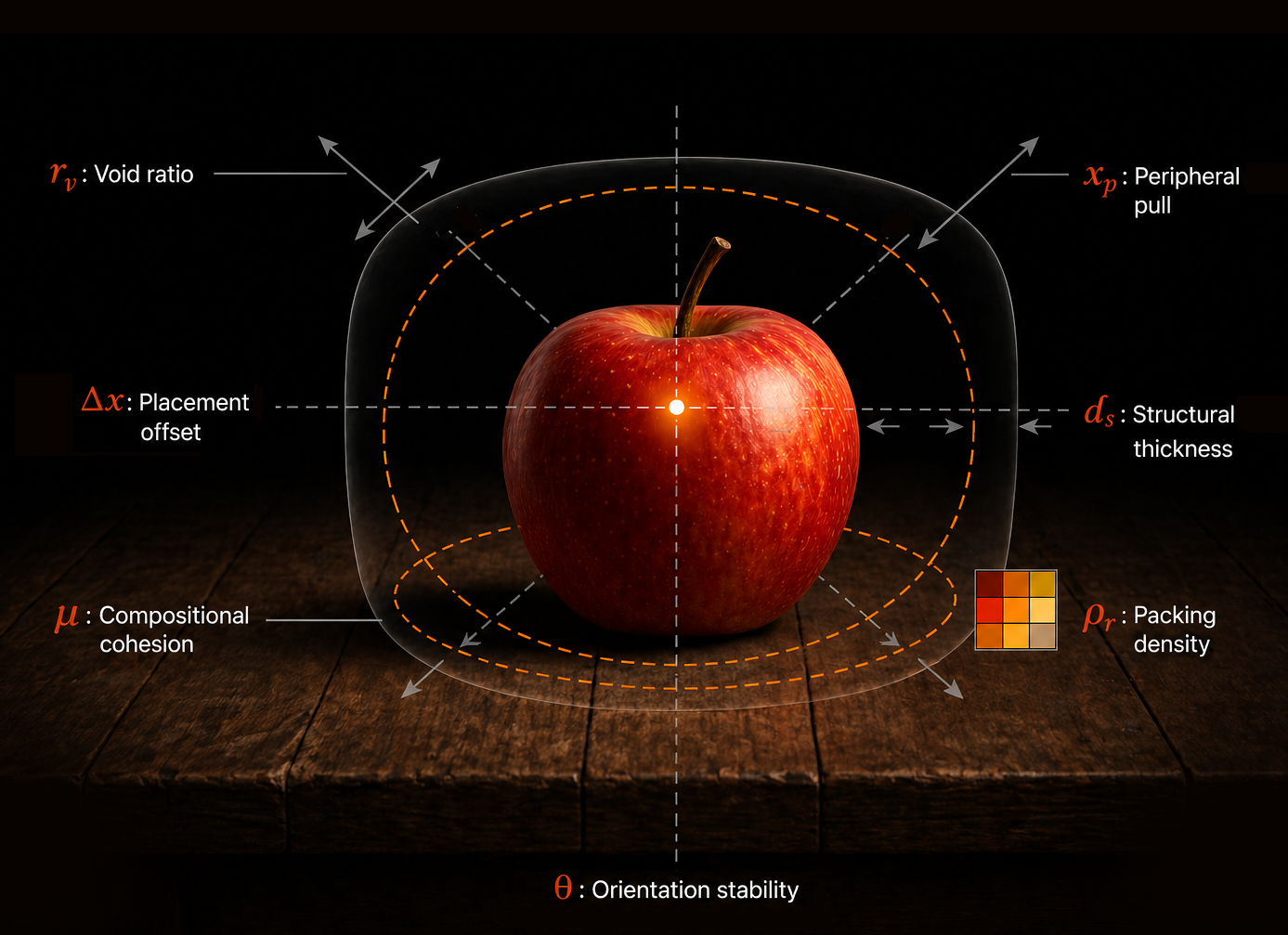
93.4%
SEM Balanced Accuracy
Carinthia semiconductor SEM · 4,579 images · 5-fold CV · first among all classical baselines
94.9%
Wafer Map Accuracy
MixedWM38 · 7,015 maps · 7.59× lift over Hu moments, which collapse to chance on wafer maps
0.9477
NIST Breach Ratio
PTD-Z envelope breach tracking across 3,402 NIST SEM degradation images. Pattern topology drift confirmed.
0
Learned Parameters
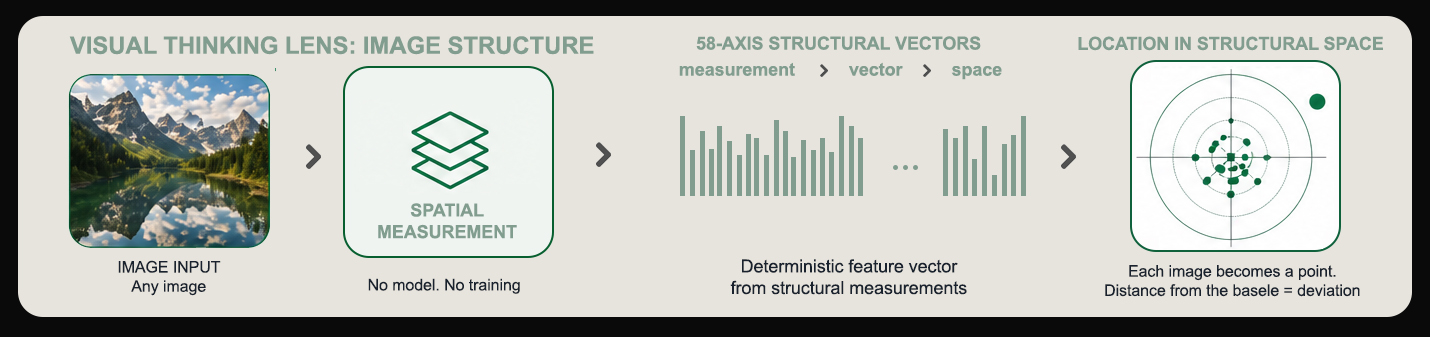
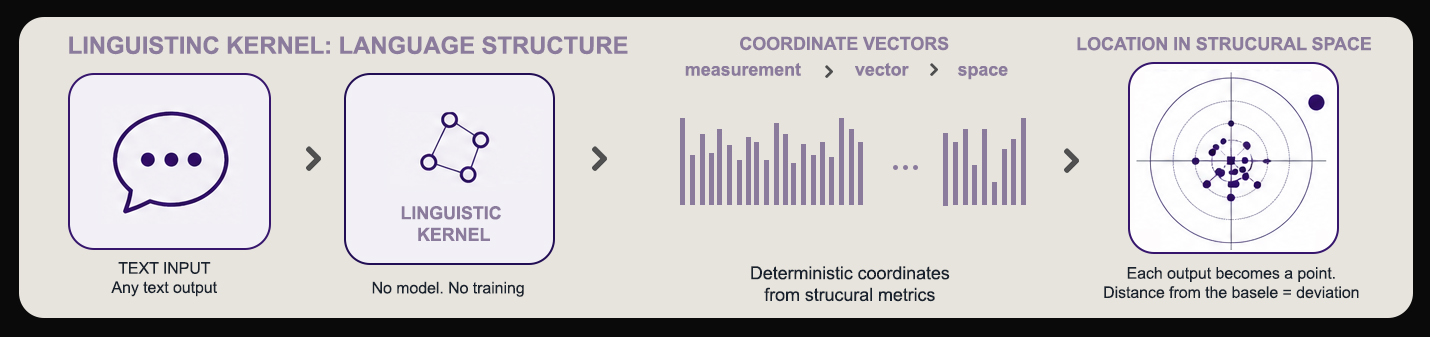
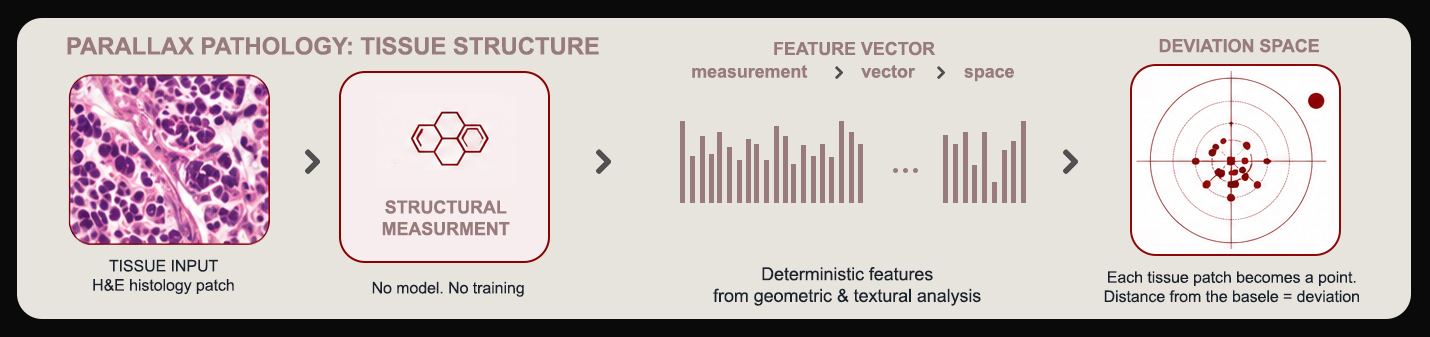
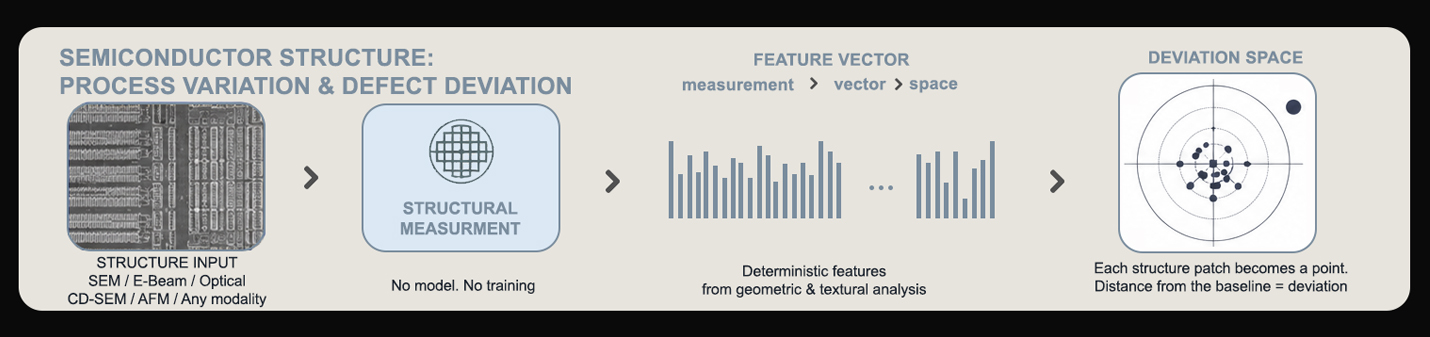
All 15 VTL coordinates derived from image formation physics. No training required across any modality.
NILS
Edge Sharpness
Normalized Image Log Slope — standard lithography metrology quantity. Strongest reference-free focus indicator (R²=0.975 against |focus|). Leads on SEM; confirms coherent defocus in aerial images.
LER
Edge Roughness
Std of lateral contour deviation, normalized by image diagonal. Identically zero on coherent simulated aerial images — an independent negative prediction confirmed before any real data was examined.
δx,y
Centroid Geometry
Intensity-weighted centroid displacement. Largest residual route after classical descriptors in Carinthia and NFFA audits. Carries mesoscale organizational signal that texture and moment descriptors do not preserve.
d_s
Spectral Spread
FFT power spectrum center of mass. Encodes spatial frequency organization — coarse vs. fine structure. Leads on density-encoded binary wafer maps where defect topology is encoded in spatial frequency.
θ
Gradient Orientation
Dominant gradient direction weighted by magnitude. Detects scratches, line patterns, oriented defects. Part of pitch/phase route — the most defensible independence route in PTD-Z audits.
Φ
Route Grammar
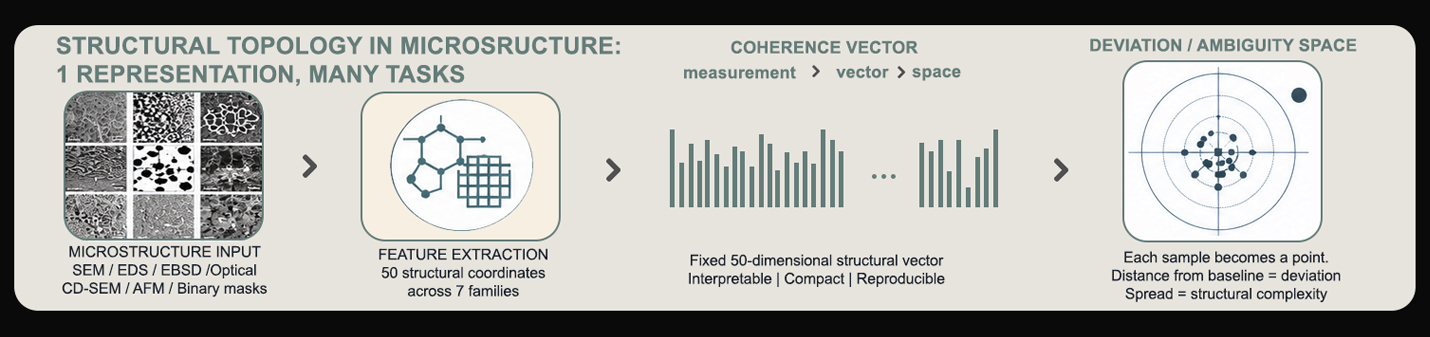
PTD-Z decomposes 15 coordinates into six route families, each carrying a process-facing hypothesis (overlay, pitch drift, etch bias, focus) and a refusal condition blocking unsupported causal claims.
Finding 01 — Cross-Modality Transfer
Coordinate dominance shifts systematically with imaging physics
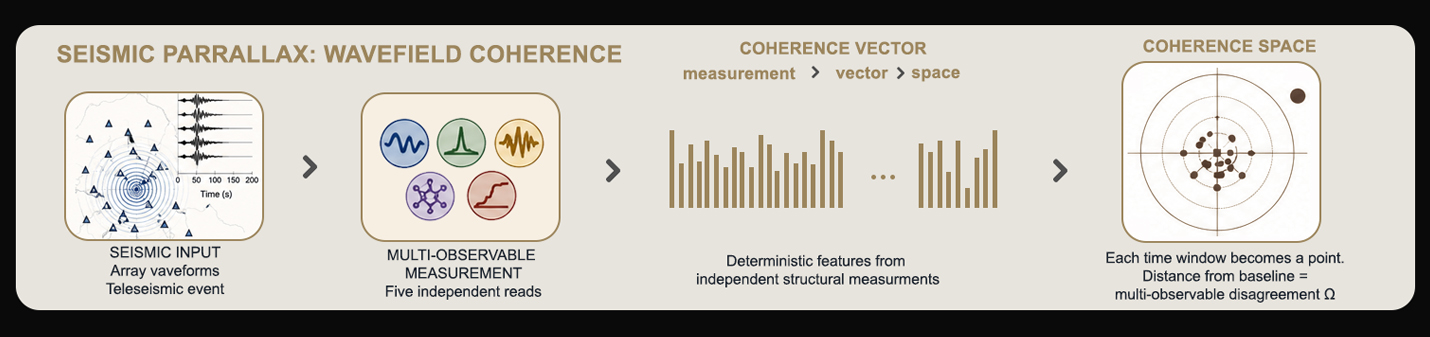
LER leads production SEM (physical edge roughness). μ and d_s dominate wafer maps (density + spatial frequency). This shift is reproducible across three independent datasets with no retraining — the framework tracks visual organization, not domain statistics.
Finding 02 — Hybrid Complementarity
Structural organization provides residual signal after classical descriptors
Adding PTD-Z to Classical_All improves Carinthia macro F1 by +0.0214 and NFFA by +0.0144. Hybrid systems outperform either alone. image_geometry and pitch_phase are the most defensible residual routes — they persist in independence audits where signal/noise and contrast drift toward overlap roles.
Finding 03 — Refusal as Method
The system knows what it cannot say
PTD-Z treats refusal as a first-class component. Each route carries a refusal condition: when the margin is thin, when the selected channel is support-heavy, when no process-linked sequence data exists. No public image dataset provides direct fab process-cause labels. PTD-Z withholds causal language when evidence is absent.
Finding 04 — Wafer Grammar
Constrained learned layer confirms coordinate signal
WM-811K wafer pattern grammar (4,149 maps, 9 classes): hand grammar alone reaches macro F1 0.5609. A constrained logistic layer over deterministic coordinates reaches 0.8859. Null-label shuffle collapses to chance — confirming the coordinates carry real class signal, not artifact.